27.08.2025 • Rim Kassab
Le clustering est une méthode d’analyse de données qui permet de mettre de l’ordre dans un ensemble hétérogène.
On peut le comparer à un placard mal rangé : quand tout tombe en vrac, on peut soit remettre en vrac… soit trier et regrouper les éléments similaires (pantalons, t-shirts, chaussures).
C’est exactement ce que fait le clustering côté données : il crée automatiquement des groupes homogènes, appelés clusters, pour transformer un chaos d’informations en ensembles lisibles et exploitables.
L’intérêt est stratégique : mieux comprendre ses clients, simplifier une campagne marketing, personnaliser une offre, détecter des comportements cachés.
Dans cet article, on vous explique :
- ce qu’est (et n’est pas) le clustering,
- quand l’utiliser,
- les grandes étapes d’un projet,
- les modèles et outils les plus courants,
- les bonnes pratiques,
- et enfin, des cas d’usage concrets
Le Clustering : c’est quoi exactement ?
Le clustering est une méthode d’analyse non supervisée qui consiste à regrouper automatiquement des données similaires entre elles, sans qu’elles aient été étiquetées au préalable.
L’objectif : transformer un ensemble hétérogène en groupes homogènes qui permettront de mieux comprendre les comportements, les profils ou les objets étudiés.
Exemple concret : un réseau de campings souhaite lancer une campagne marketing. Plutôt que de cibler chaque camping individuellement, le clustering permet de les regrouper par critères de similarité (taille, chiffre d’affaires, localisation…) et d’adresser une stratégie adaptée à chaque groupe.
Le clustering est souvent confondu avec d’autres méthodes :
- Ce n’est pas une segmentation prédéfinie : dans une segmentation marketing classique, on définit à l’avance des critères (“clients premium”, “familles avec enfants”, etc.) et on classe ensuite les individus selon ces règles. Le clustering, lui, laisse l’algorithme découvrir spontanément les regroupements en fonction des données.
- Ce n’est pas de la classification supervisée : l’apprentissage supervisé cherche à prédire une étiquette connue à partir de données historiques (par exemple, anticiper si un client risque de churner). Le clustering ne prédit pas, il explore. Son rôle est de révéler des structures cachées dans les données.
En résumé, le clustering ne consiste pas à imposer une logique métier à vos données, mais à laisser émerger naturellement des groupes cohérents.
Quand utiliser la data clustering ?
Le clustering devient particulièrement utile lorsque l’on dispose d’un grand volume de données brutes, sans segmentation préalable.
Dans ces situations, il permet d’identifier des structures cachées, de mettre en évidence des similitudes invisibles à l’œil nu, et de créer des regroupements pertinents pour le métier.
Il est particulièrement adapté quand les données sont très dispersées et peu comparables entre elles.
Si au contraire les données sont toutes semblables (par exemple une armoire qui ne contient que des t-shirts), il est difficile de créer des clusters vraiment distincts et utiles.
Exemples de cas concrets
- Segmentation clients : regrouper des profils de consommation similaires, par exemple : ceux qui achètent surtout du bio, ceux qui consomment beaucoup de viande, les acheteurs occasionnels, les clients qui ne profitent que des promotions…
- Marketing personnalisé : lorsqu’on identifie des clients sportifs, on peut leur proposer des articles liés à leur pratique (vêtements, accessoires) ou leur mettre en avant des promotions ciblées.
Ces regroupements permettent d’aller plus loin qu’une simple segmentation manuelle et d’activer des actions concrètes : meilleure personnalisation des campagnes, optimisation de l’offre ou encore amélioration de la relation client.
Les grandes étapes d’un projet de clustering
Un projet de clustering suit une logique progressive : on part des données brutes, on les prépare, puis on applique un algorithme pour obtenir des regroupements interprétables et actionnables.
1️⃣Compréhension métier
Avant même d’ouvrir les données, il faut clarifier l’objectif business. Le clustering n’a pas vocation à être un exercice purement technique : il doit répondre à une question concrète.
- En marketing : personnaliser les campagnes pour éviter de multiplier les ciblages manuels.
- En e-commerce : mieux connaître les profils clients et adapter les recommandations.
- En stratégie : identifier des segments de valeur ou des zones à fort potentiel.
Sans cette étape, on risque d’obtenir des clusters intéressants sur le papier… mais impossibles à exploiter.
2️⃣Exploration des données
Une fois l’objectif défini, on s’intéresse aux sources disponibles : CRM, e-commerce, ERP, analytics, données produits…
Cette étape permet de :
- savoir quelles informations sont réellement accessibles,
- vérifier leur qualité et leur fraîcheur,
- centraliser dans un datawarehouse pour éviter les silos.
C’est là que l’on décide aussi quels indicateurs calculer (panier moyen, fréquence d’achat, marge, saisonnalité…), qui serviront de base à la création des clusters.
3️⃣Prétraitement
Les données brutes sont rarement exploitables en l’état. Le prétraitement consiste à les rendre fiables et comparables :
- nettoyer les anomalies et supprimer les outliers (données aberrantes) qui faussent l’algorithme,
- normaliser les échelles pour que toutes les variables aient le même poids (par ex. CA vs. fréquence),
- transformer les données non numériques grâce à des encodages,
- réduire la complexité grâce à la PCA (Analyse en Composantes Principales), qui conserve l’essentiel de l’information tout en éliminant le bruit.
Cette étape est cruciale : un clustering mal préparé donnera des groupes incohérents ou inutilisables côté métier.
4️⃣Détermination du nombre de clusters
Cette étape sert à répondre à une question clé : combien de groupes faut-il créer pour que l’analyse ait du sens ?
- Trop de clusters → la lecture devient illisible et difficile à exploiter.
- Trop peu → on perd des nuances importantes.
Pour trouver le bon équilibre, on utilise des méthodes comme :
- La méthode du coude (elbow method) : elle mesure la “perte d’information” quand on réduit le nombre de clusters. Le point où la courbe commence à se stabiliser indique un nombre de groupes pertinent.
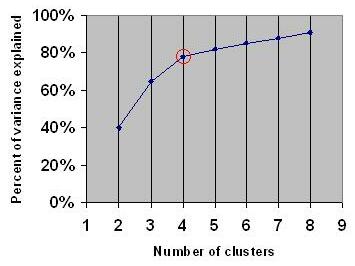
- Le silhouette score : il mesure la cohérence d’un cluster. Plus le score est proche de 1, plus les éléments d’un groupe sont proches entre eux et éloignés des autres.
Ces indicateurs permettent de choisir un nombre de clusters exploitable par le métier, ni trop complexe, ni trop simpliste.
5️⃣ Choix de l’algorithme
Une fois le nombre de clusters estimé, il faut choisir la méthode de regroupement la plus adaptée aux données :
- K-means : l’algorithme de référence. Il calcule des “centres de gravité” et assigne chaque donnée au centre le plus proche. Résultat : des groupes compacts et lisibles, idéals pour des cas comme la segmentation clients.
- DBSCAN : utile quand les données sont bruitées ou que les clusters ont des formes irrégulières. Il a aussi l’avantage de mettre de côté les points “isolés” (outliers) qui pourraient fausser l’analyse.
- Méthodes hiérarchiques : elles construisent des regroupements de manière progressive et produisent un dendrogramme (arbre de rapprochement). Très visuel, ce type de méthode est souvent utilisé en phase exploratoire pour comprendre la structure globale des données.
Ces algorithmes sont disponibles dans des bibliothèques spécialisées comme scikit-learn (Python), qui offrent à la fois simplicité d’utilisation et fiabilité pour des projets data en entreprise.
6️⃣ Création et analyse des clusters
Une fois l’algorithme appliqué, les premiers regroupements apparaissent. Mais un cluster n’a de valeur que si on peut l’interpréter et le relier à des actions concrètes.
>> Étiquetage métier : chaque cluster doit recevoir une “identité” compréhensible pour les équipes. Par exemple :
- “Clients fidèles mensuels” : ceux qui achètent au moins une fois par mois,
- “Promo-addicts” : ceux qui n’achètent qu’en promotion,
- “Saisonniers Noël” : ceux qui achètent uniquement en fin d’année.
>> Analyse des comportements moyens : on calcule les indicateurs clés (fréquence d’achat, panier moyen, types de produits achetés) pour résumer le profil de chaque groupe.
>> Lien avec les décisions métiers :
- en marketing → adapter les campagnes (un cluster “sportifs” reçoit des offres ciblées sur des articles de sport),
- en e-commerce → personnaliser les recommandations produits,
- en retail → différencier les assortiments par points de vente,
- en stratégie → identifier les clients à forte valeur ou ceux à risque de churn.
En résumé, cette étape transforme un simple regroupement algorithmique en segments activables par les équipes marketing, e-commerce ou business.
7️⃣Restitution et validation
L’analyse ne s’arrête pas à la génération de clusters : il faut les expliquer et les faire valider par les métiers pour qu’ils soient réellement utiles.
- Visualisation des résultats : les clusters sont représentés à l’aide de graphiques accessibles, comme des nuages de points (scatter plots après réduction de dimension), ou des comparaisons de moyennes par indicateur clé. Ces représentations permettent de voir rapidement la séparation entre groupes et leurs caractéristiques principales.
- Communication claire : inutile d’entrer dans les détails techniques des algorithmes ou des scores. L’essentiel est de présenter des catégories lisibles, avec des labels explicites (“fidèles mensuels”, “acheteurs saisonniers”, “promo-addicts”).
- Workshops métiers : une étape cruciale pour s’assurer que les clusters ont du sens côté business. Les équipes marketing, produit ou commerce peuvent demander des ajustements, par exemple isoler un segment spécifique (“clients 100 % bio”) ou regrouper différemment.
- Itérations possibles : si les résultats ne collent pas aux besoins, on peut relancer le processus : changer d’algorithme, ajuster le nombre de clusters ou modifier les variables analysées.
En bref, la restitution transforme une analyse data en outil décisionnel concret : les équipes comprennent les groupes obtenus et savent comment les exploiter dans leurs actions quotidiennes.
Bonnes pratiques
Savoir pourquoi on démarre un clustering
Le clustering ne doit pas être un exercice “par curiosité”. Avant de se lancer, il faut avoir une idée claire de l’usage métier attendu :
- Découvrir des profils clients méconnus,
- Rationaliser les campagnes marketing,
- Identifier des opportunités produits,
- Optimiser un réseau ou un portefeuille.
Sans objectif précis, on risque de produire de beaux graphiques… mais sans impact concret.
Expliquer simplement aux non-experts
Un cluster n’a de valeur que s’il est compris et utilisé. Inutile d’entrer dans les détails d’algorithmes ou de scores : l’important est de donner des labels parlants.
Par exemple :
- “Acheteurs fidèles mensuels” plutôt que “Cluster 1”,
- “Promo-addicts” plutôt que “Cluster 2”.
Ce langage clair permet aux équipes marketing, e-commerce ou business de s’approprier les résultats et d’agir rapidement.
Prendre le temps d’interpréter
Un clustering n’est pas une vérité absolue : c’est une proposition de regroupement. Il faut toujours prendre le temps d’analyser les résultats, d’en discuter avec les métiers, et parfois d’itérer :
- en ajustant les variables prises en compte,
- en testant un autre nombre de clusters,
- ou même en changeant d’algorithme si nécessaire.
L’objectif n’est pas d’obtenir des “clusters parfaits”, mais des clusters utiles et actionnables.
Valider la qualité des clusters
Avoir des regroupements ne suffit pas : encore faut-il vérifier qu’ils tiennent la route.
- Silhouette score : plus proche de 1 → plus les éléments d’un cluster sont cohérents entre eux et éloignés des autres.
- Indice de Davies-Bouldin : plus bas → meilleure séparation entre groupes.
- Assez de données : sans volume suffisant ou sans variabilité, les clusters risquent d’être instables et peu exploitables.
Ces métriques techniques sont utiles en interne, mais ce qui compte in fine, c’est que les clusters soient validés côté métier : est-ce que ces regroupements correspondent à une réalité observable ?
Conclusion : ranger pour mieux décider
Le clustering, c’est l’art de transformer le désordre en structures utiles. Comme un placard qu’on trie, il permet de passer du chaos de données à des groupes cohérents, compréhensibles et activables.
Bien utilisé, il devient un levier pour :
- mieux comprendre ses clients,
- personnaliser ses campagnes,
- optimiser ses offres et réseaux,
- et prendre des décisions fondées sur des données concrètes.
Mais comme tout rangement, il demande méthode, régularité et les bons outils.
👉 Chez Spiriit, nous aidons les entreprises à transformer leurs données en décisions actionnables. Si vous souhaitez lancer un projet data – ou simplement évaluer le potentiel du clustering dans votre organisation – notre équipe est à votre écoute pour en discuter.
Contactez-nous.

partager
Plus d’articles !
Plongez dans nos articles pour découvrir des insights captivants !